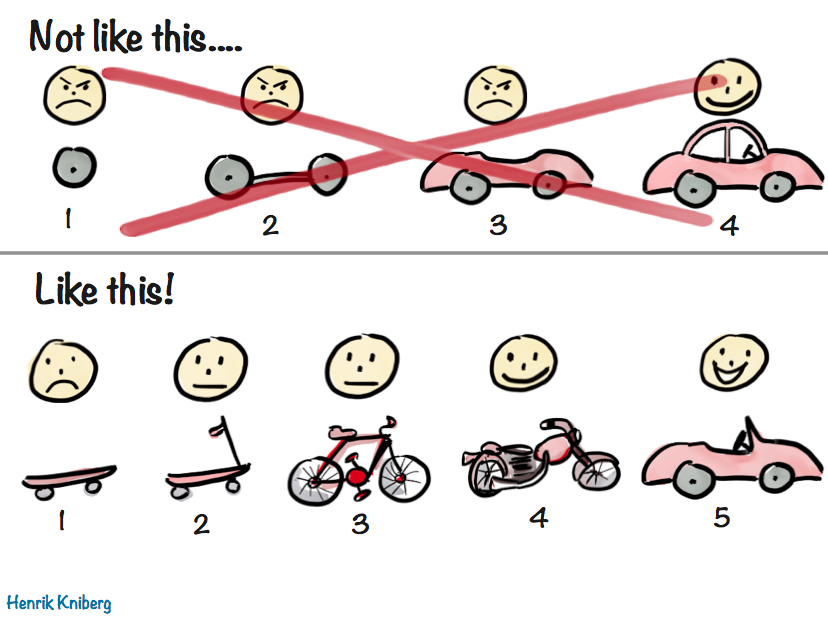
Delivering working software in the hands of the customer is one of the core principles behind agile software development, and one that we follow at Webjet. This means teams break down their work into bite sized chunks and deliver working chunks iteratively.
But back when we started our agile journey, this usually meant working on the back end, followed by working on the front end. As you might have guessed it the “working software” was only delivered at or close to the very end. Not ideal.
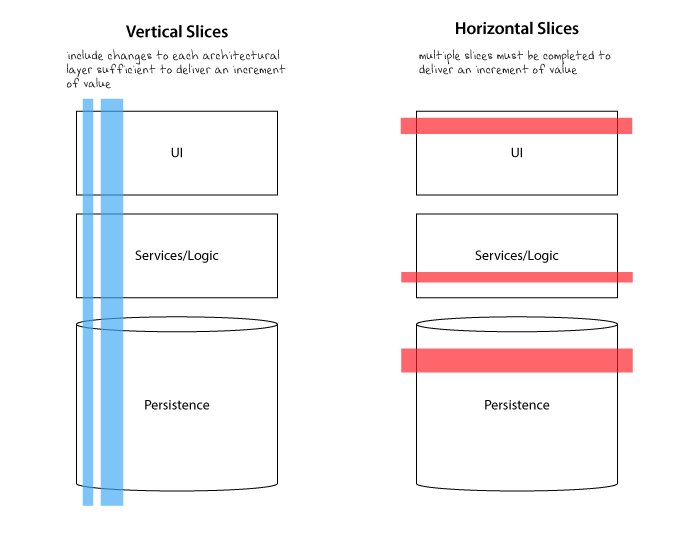
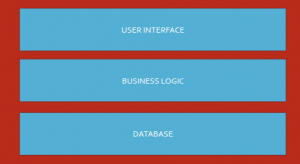
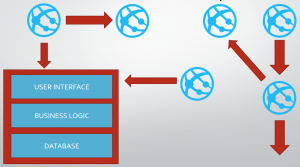
I didn’t know the word for it at the time, but we were doing Horizontal Slicing, i.e. breaking down work based on its functional area, without taking a holistic end to end approach. We were iteratively delivering a car by delivering only the wheels first.
MVP
Going back to the core principles, we looked at how we can deliver a true MVP, something that provides value to the customer and to the company, something that we are happy to have in production. We came across the concept of vertical slicing, which helped us articulate the MVP approach.
Vertical and Horizontal Slicing
Using the example of creating a new flight search experience for mobile browsers, I will share our thinking and how we approached vertical slicing, which will help crystalize the concept
Our flight search experience for mobile needed an update. The incumbent design was a copy of the legacy app experience, built using JQuery mobile integrated into our monolith. This made making changes more complicated and take longer to deliver. It was not aligned with our strategy of splitting it into independently deployable microservices.
Old Mobile Search
We decided to create a new React based service to render the responsive front end coupled with a new search API. This would make iterative changes less complex and faster to market. But there were a lot of features to deliver, multiple result views, and the integration with the legacy platform.
New Mobile Search
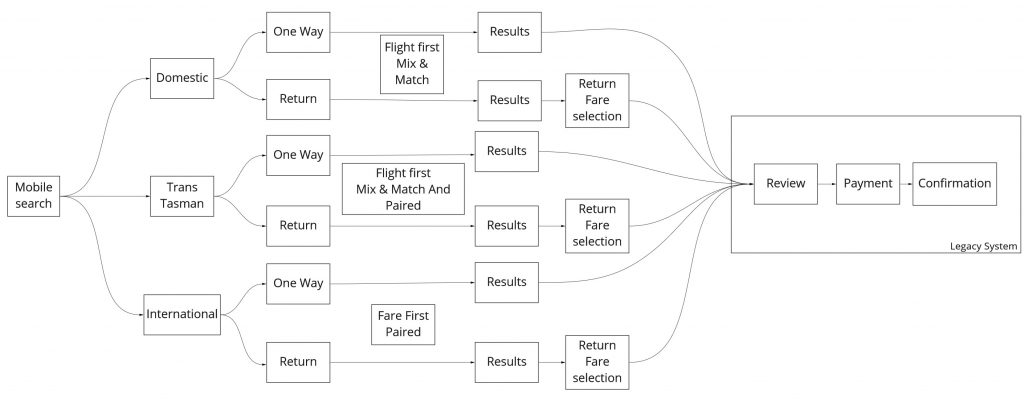
To help define the workflow the team documented the high level workflow
High level workflow for mobile Flight Search
To help guide our decision in defining the MVP we looked at the following
Data on the booking mix i.e. domestic vs Trans-Tasman vs international, one-way vs return, passenger mix etc
Key path dependencies
An MVP that delivers value to the customer
The following were the results of the analysis
A large majority of the bookings were domestic, so the real value from a customer’s POV lay there
As domestic volume was higher any issues in the new path could be amplified
A wide range of passenger mixes existed, e.g. 1 adult, 2 adult and 1 child, 2 adults etc
Integrating into the legacy shopping cart was a key dependency. Until now the search and booking happened in the same platform.
The incumbent mobile design was quite dated and had limited functionality. Customers could only sort on 4 attributes and there was no filtering
Based on this we determined the first slice as a
Single one-way adult search: limits the scope of the customer cohort
For a medium capacity route: reduces the risk of unexpected failures and provides value to the customer
With just the sort functionality currently supported: limits the feature set that needs to be built
That can be searched and booked end to end: reduces key path dependency
MVP identified in Mobile Flight Search
The team went on to develop this MVP and release it to the customers in a fraction of the time of the full design build. After based on feedback from data gathered, we iteratively added more features starting with supporting return search and result filtering. The team could quickly support more routes and passenger mixes using feature flags as their confidence grew in the new services.
Not only were we able to deliver value iteratively, but since we only focused on a narrow path it gave other advantages
Validation of the new design in the hands of the customers
The team did not need to develop a Trans-Tasman or an international design till much later
Increased confidence in monitoring and alerting of the service as the load slowly increase
Looking back at our approach the key element that made this a success was a strong engagement with the business stake holders. Having their input and buy in to delivering a fraction of the promised functionality in the customer’s hands was crucial. We used real metrics to measure customer satisfaction with our new design. It also helped us tweak features that were causing issues and iterate on the features that were well received.
Without it we would be relegated to releasing in our UAT environment which would not give true confidence in the design, and customer would have waited months to get any value.
If you are interested in joining our team, we are hiring! Our current job postings can be found here: https://lnkd.in/gycBPXPx
At Webjet’s UnITed Conference, Lachlan McKerrow went through the history of the organisation’s 10-year agile journey, from being a siloed organisation practising waterfall processes for deploying monoliths, to having adaptive, constantly learning cross-functional teams, iteratively delivering microservices.
Pre-Agile
Before 2011, Webjet’s engineering team was set up much differently than how it is today. There were teams of developers, testers, and ITOps (plus a part-time Business Analysts) sitting in their own workspaces and there was little collaboration. The system was a monolith, know as TSA (Travel Service Aggregator), and deliverables were “thrown over the wall”.
Programming was done solo. The process was regimented, and individuals followed the plan, with tech leaders and managers advising teams what to do. None of the staff asked questions. Designs were done in a closed room by management, and each mockup and specifications had to be signed-off by senior management. If mockup was wrong, it was slow to change. Things would sit on the shelf for long due to the hoops they had to go through.
Delivery was done over an 8 to 12-week cycle, a “Big Bang” with a batch of things being brought to production. Many times, if things went wrong, everything had to roll back, and there would be finger-pointing that ended with “that’s what you told me to do.” There was no accountability by individuals or teams.
It was a long and torturous process to go from development to production.
Trying Out Agile
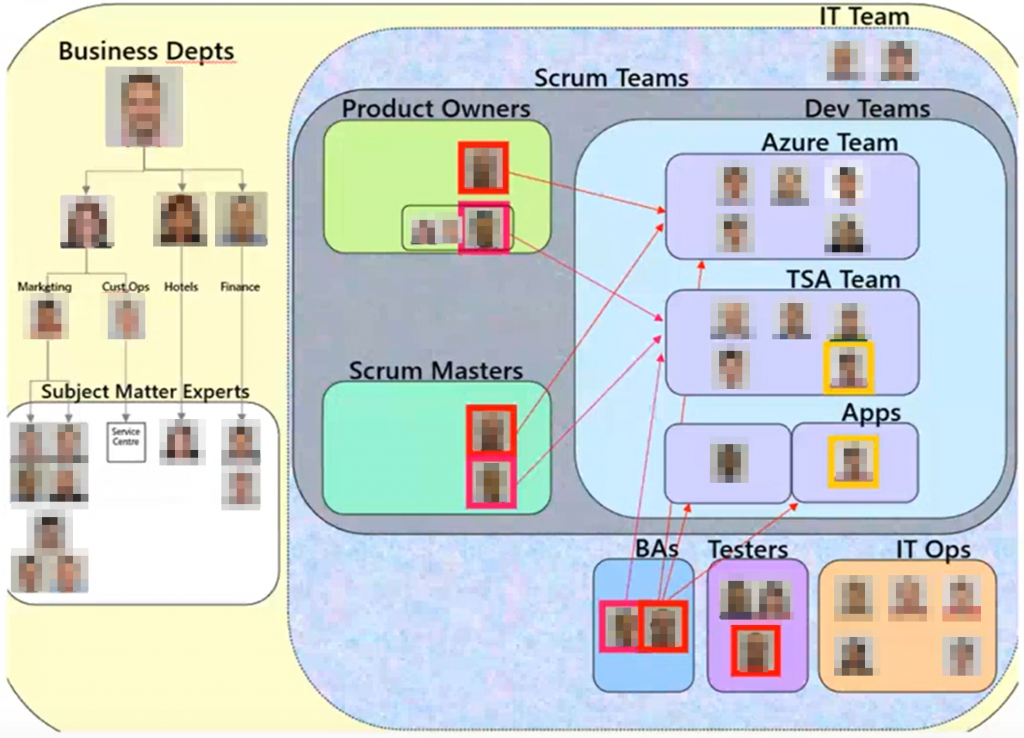
In 2011, Webjet started trying out the agile way. By then, the team had 11 developers and 1.5 BA’s. The development teams were then reorganised, and divided into two streams: Scrum (for Project Contrail), with 5 in the Azure team, and Waterfall, with 4.5 developers in the TSA team, 1.5 in Apps, and 5 in ITOps, with some people having multiple roles.
The design process remained the same. It was still management-centred, done in a closed room, and each mock still had to be signed off by senior management.
The Azure team developed the flights path as a mobile site, and the TSA and ITOps teams kept the desktop site running. The release was on 8.5-week cycle. There were modest enhancements to the desktop site as there were fewer resources. From the process of delivering the mobile site, however, came some significant insights.
The First Ah-Ha Moment
In late 2012, early 2013, Contrail was the first attempt to put something into the cloud (through Azure), where Webjet was the first customer commercially signed by Microsoft. The development partner, Readify, was practising Scrum, and Webjet thought that this might be the way forward. The mobile site, unfortunately, didn’t go to production, as ITOps wasn’t involved. They couldn’t support it, and if something happened, they wouldn’t know how to fix it.
Scrum was trialled for one team, before getting others to do the same. This made development effort costly, but the learning was valuable.
How Webjet Was Organised
Going Agile
After learning from the Contrail project and the first attempt at Scrum, the teams were again reorganised. A dedicated product owner was brought on board. Two large development teams (named Snipers and Samurai, each with a Business Analyst) and a product support team (named SWAT) was established. Testers and ITOps remained in their separate teams. There was a 6-8 week delivery cycle for the monolith.
Production Support Daily Process
The teams got Professional Scrum Master training, and Scrum ceremonies (such as planning poker) were followed. There were visits to REA Group and Seek to see how they operated, and adopted some of their practices. There was a move away from Scrum to Lean, then to Kanban. The design was still management-centred, but the mocks didn’t have to be signed-off by senior management anymore. There was now an emphasis on user-centred design, with User eXperience expertise brought in. Feature toggles were introduced to allow code to be put live on production but turned off.
DevOps role was then added to each team. New systems like Octopus (aka the Kraken, as it kept breaking things), Git, ARR, and TeamCity were installed. The “bus” (a concept borrowed from Seek) was created for the deployment of the monolith, scheduled weekly.
The outcome wasn’t very good. Planning meetings were hated, and no one wanted to go to them. Estimates were not accurate. There was sandbagging to make burndown charts look good by overestimating. No one wanted to rotate through the SWAT team. There was diffused accountability across teams. There were, however, reduced time on ceremonies and planning meetings.
As for the design process, adjusting for mock-up errors was easier, and the focus was now on the customer, something that the REA Group pointed out was key. The Pattern Library was introduced for consistency and ease of front-end development.
For delivery, it was still a Big Bang delivery, with some rollbacks. Deployments gradually became easier, although they still had problems. However, when things went wrong, the focus was now on what’s needed to do to fix it rather than finger-pointing. The bus started to depart every 2 to 3 weeks.
The Second Ah-Ha Moment
In early 2016, the second major realisation is that Webjet was “doing” agile, but not “being” agile. It was a case of “monkey-see, monkey-do” with following practices and processes of agile without an understanding of why it works.
An Agile Coach was brought in to review, and Webjet was told that the practice of agile was fine, but like everyone, you can do better. What was missing was having better awareness and a deeper understanding of Agile’s 4 values and 12 principles from the Agile Manifesto. To be truly agile, it has to be inserted into the organisation’s DNA.
The Agile Manifesto
Being Agile
The teams were now reorganised into line-of-business cross-functional delivery teams, taking a cue from Spotify. Quality Assurance was now part of the same team, disbanding the test teams. DevOps moved from these teams and a Platform team was created. Responsibility for testing and deployment of microservices was fully with the delivery team, and ITOps was no longer involved in this process. There was an office redesign with collaborative workspaces. The organisation was organised into teams and guilds (grouped by roles).
UI resources were attached to teams for a project instead of sitting inside the team. UX optimised workflows with the aid of user testing. UI and UX improved all booking paths through consistency (with the pattern library). There was a weekly cycle for monoliths, and a daily cycle for microservices.
The process kept on evolving, adapting to the needs of the organisation. The strengths of Kanban practices and Scrum sprints were brought together as “Webban”. Standups started with a report on production support issues by the rostered team member (which included Quality Assurance). Psychological safety was promoted to enhance the learning process. Servant leadership, where leaders support and guide instead of telling what to do, was adopted. Business Analyst’s asked the 5 Why’s to identify the actual problem and core value, and who the customer is.
There was a shift of quality to the left. Business and UX were doing the ideation and Business Analysts and Solution Architects joining to refine it. Product Backlog Items (PBIs) were written in Behavioural Driven Design (BDD) format (Given/When/Then format) and reviewed by Quality Assurance. Kick-off meetings were held. Hack Days were introduced to further encourage collaboration and bring down siloes in the office.
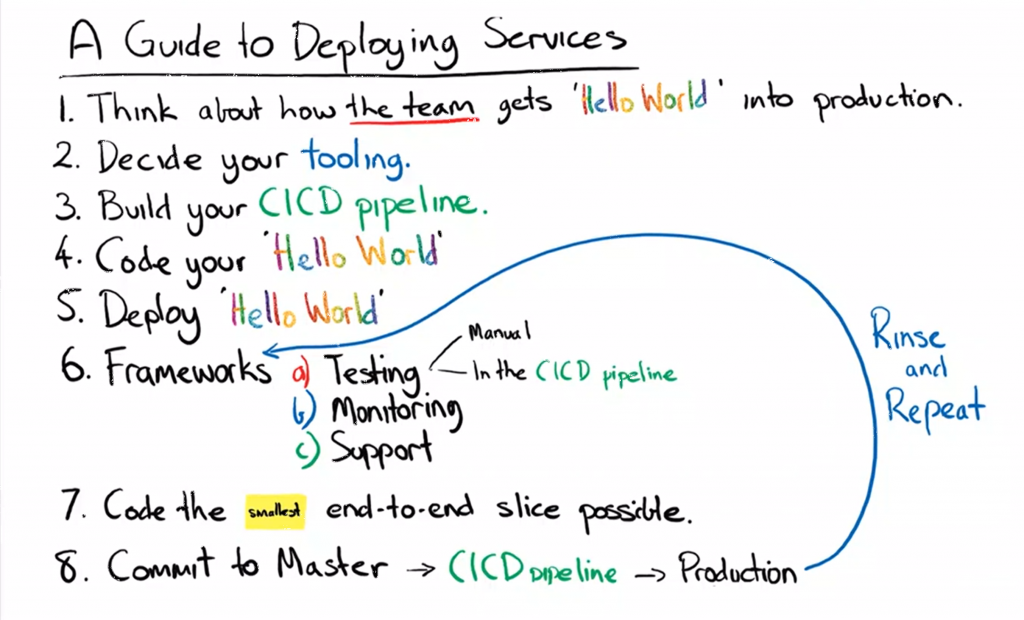
Quality Assurance took the role of bus drivers for the monolith. A guide to developing microservices was written, and Continuous Integration/Continuous Delivery (CI/CD) pipelines were made to work with development/production configuration from the get-go. Teams had to think of how to get “Hello World” to production, and only after this is done do they start writing feature code.
A Guide for Delivering and Deploying Microservices
As a result of all of this, teams have become more empowered, taking ownership and accountability. Team members developed T-shaped skillsets, having the breadth of knowledge to cover things when necessary, but having deep knowledge based on their roles.
For release, things were released iteratively. For example, for mobile search, the feature was first enabled only for one route, to see how customers behave, address problems, and assess the outcomes. If things went wrong in production, there was a calm, supportive approach to getting it sorted, with a Root Cause Analysis made to gain learning. This happened when Flights First was released to production on a Friday at 3pm with only a development config in place, not a production one. Holding off the release to Monday morning for more development environment testing wouldn’t have uncovered the issue.
The Third Ah-Ha Moment
The third major realisation, which came in mid-2019, is that there is no framework of agile that fully fits anyone and that the practice of Agile can’t stand still. It’s important to look around and see what is out there.
Being More Agile
In 2019, further refinement on agility came with the introduction of Vertical Slicing, introduced with Paper Planes and Elephant Carpaccio workshop by Alistair Coburn. The guide to deploying microservices was enhanced to emphasize getting value to the customers as early as possible. There were sessions on Pair Programming and the Heart of Agile.
Heart of Agile
Business Analysts are designated as Delivery Drivers, responsible for bringing features to production. Cypress was introduced as a replacement for Hymie (our in-house automated testing system), bringing the full spectrum of automated testing to the individual teams.
Conclusion
A framework can’t be simply taken from another organisation, turn it into a template, and shoehorn it into process and practices. The approach is to look at what others have done and is found to be useful, and consider if it is a good fit for the company’s environment and culture, as well as letting go of old practices. It’s a constant evolution as teams, work, and business demands change, continually adapting the process. In all of these, always thinking of customers first.
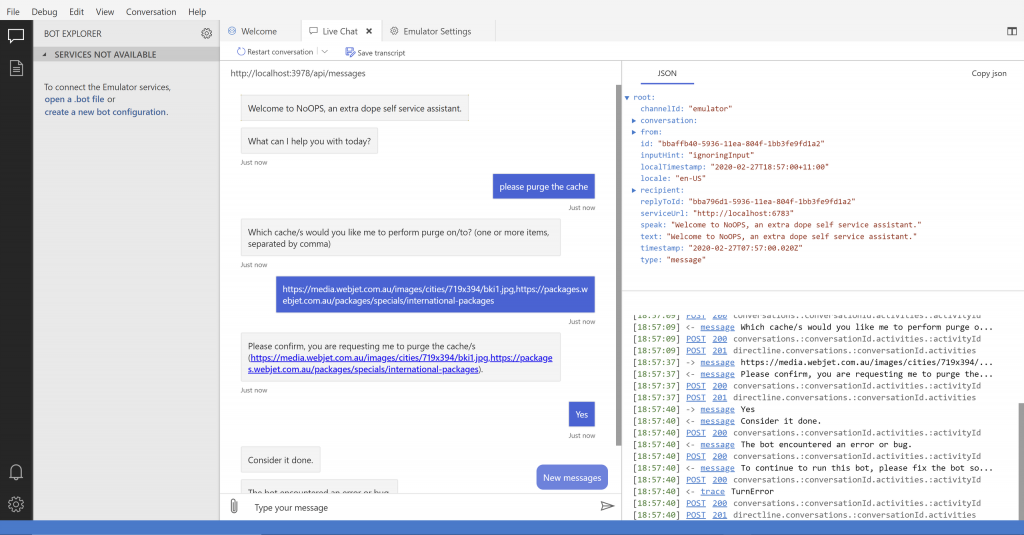
During last February’s HackDay, the NoOps team delivered a prototype version of the NoOps Bot. The NoOps bot is a self-service system that allows an MS Teams user to issue simple commands to be performed by backend Platform services.
The system has two main components, the front-end conversational bot, which processes the messages, and the back-end plugin services, which perform the work requested by the user.
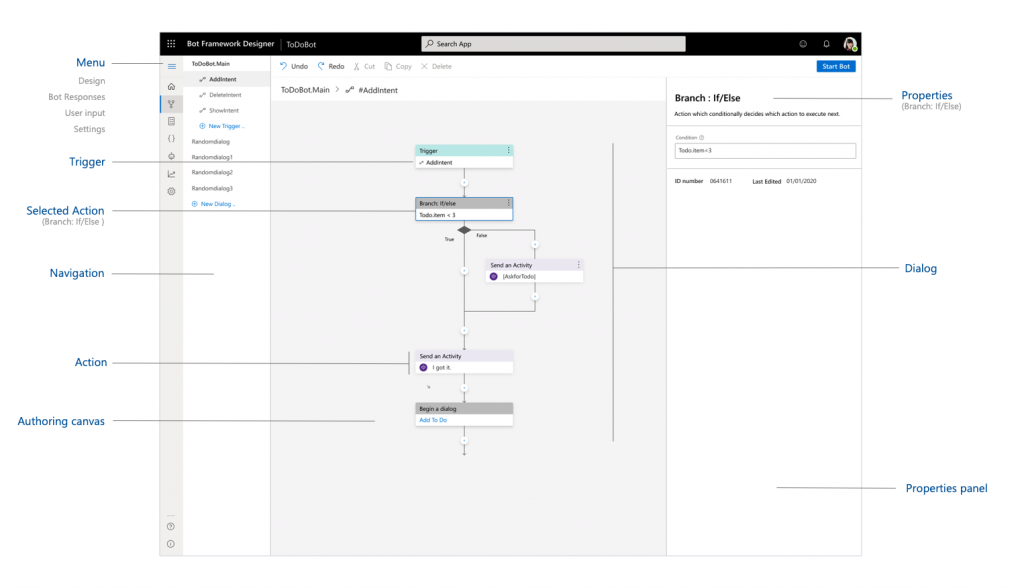
NoOps bot, accessed via the Bot Framework Emulator
The Microsoft Bot Framework
To develop the NoOps bot, we used the MS Bot Framework. It is a set of services, tools, and SDKs that provides a foundation for developers to build AI bots.
The following are the main components of the Bot service app.
Hosted in Azure, the Bot Connector Service allows the connection to channels (such as MS Teams) configured in the Azure portal.
The entry point to the bot service, the Bot Framework Adapter sends and receives activities to/from the Bot Connector Service.
The Root Bot handles activities (information passed between the bot and the channel, such as a message or a new connection from a user) and runs dialogs.
Dialogs drive the sequence of interaction between the user and the bot, breaking it down into individual steps that display or receive messages (and connect to the Recognizer.)
The Recognizer takes messages and identifies intents by connecting to an Azure AI service, the Language Understanding Intelligent Service (LUIS).
Intents and Dialogs
For the HackDay version, the NoOps bot could process two types of requests: purge Cloudflare cache and recycle IIS application pool for our UAT site. The current version of NoOps can process an additional request: show the latest Webjet news (from Google news.)
Each of these requests is defined in the app as an intent, and each intent leads to a separate dialog, as they have varied interaction steps.
News Dialog. The news feature is a single-step process. Once the news intent is identified, it connects to Google News to retrieve an RSS feed and displays the top 5 news titles and links.
Recycle UAT Dialog. This is a two-step process. The bot confirms to the user whether he/she wishes to recycle UAT, presenting a yes/no prompt, and, if yes is clicked, proceeds to send an HTTP POST request to the Recycle UAT service.
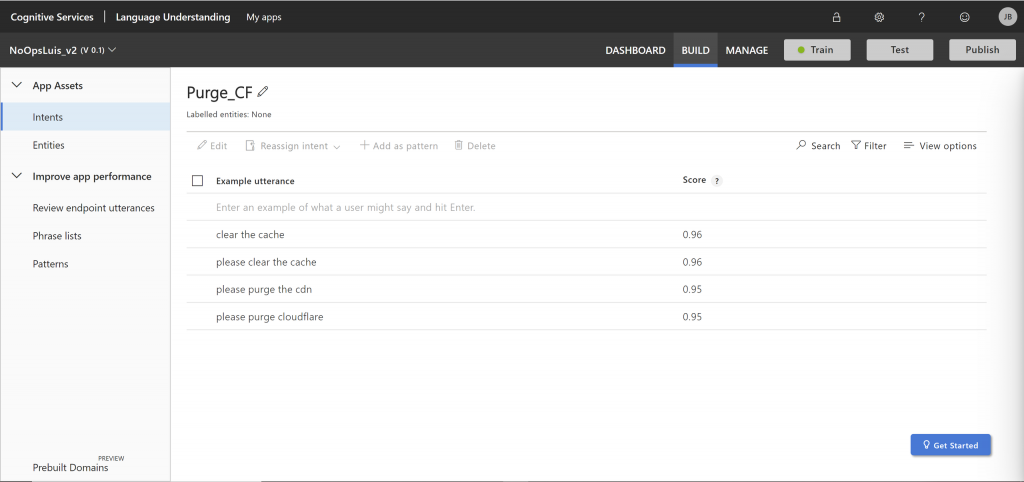
Purge Cloudflare Cache Dialog. This has three steps. The bot prompts the user to provide the CDN resource to purge (separated by commas). Then, it confirms to the user whether he/she wishes to proceed (with a yes/no prompt similar to Recycle UAT), and if affirmative, proceeds to send an HTTP POST request to the Purge Cloudflare plugin service, providing the URLs in the payload.
These three dialogs do not require AI to go through their steps. In the future, there may be more intelligence required to perform more complex tasks. But for now, the main use of AI in the NoOps bot is understanding the initial input from the user, received by the Main Dialog, to determine the user’s intent from the natural language message entered. For this, the Bot interfaces with Azure’s Language Understanding Intelligent Service (LUIS).
Language Understanding Intelligent Service (LUIS)
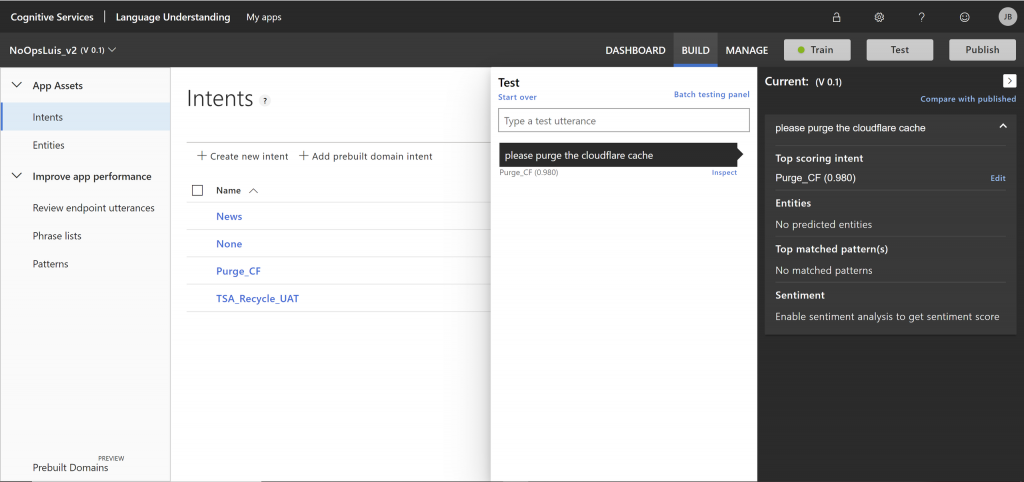
LUIS is an Azure AI product for building and running natural language models. It takes an utterance (text input) and returns one or more intents, each with a score on how strong the utterance aligns with the language associated with the intent. If a score is too low, the Bot is configured to say that it does not understand the request.
The current NoOps model has three intents: News, Purge_CF, and TSA_Recycle_UAT. Each of these intents has a list of utterances that are used to train the AI to help it understand the text. LUIS also stores a history of messages it has received, including those it was unable to understand, and they can be used as inputs to add to the list and improve the model.
Bot Framework Composer
The current NoOps bot is built with Python. A future version may instead be built using the Bot Framework Composer. Instead of developing the dialogs through Python code, the Bot Framework Composer provides a graphical interface to represent the conversation flow, and generates the logic in a JSON format to be consumed by the Bot service. This makes it easier for teams to build their own bots.
Skills
Beyond simple dialogs, the Bot framework allows extension and reuse through skills. Skills are composable bots, each running as a separate service, that are linked to a central bot. This allows teams to maintain their own bots (as microservices) but are still all connected to one central channel. Microsoft has created a number of out-of-the-box skills that have productivity capabilities such as managing calendars, sending emails, or providing map information.
Possible Future Applications
The NoOps bot is but one of the many possible applications of the Bot Framework for WebJet. It is interesting to note that one of the samples in the Bot Framework SDK tutorial is Flight Booking. Bot frameworks like the MS Bot Framework are an alternative to packaged AI chatbot solutions. With the recent spike of LivePerson use due to travel bans, it can someday also be able to help reduce the load of Customer Centre, and provide great value to Webjet and its customers.
Since the release of NoOps Bot, we have received a number of feature requests, with a few posing some implementation challenges.
In the past five years, there’s been a big shift towards microservices and containers in the technology space. Microservices allow us to decouple domain knowledge between services, keeping them simple which increases velocity at which we are able to place software in customers hands. Being able to deliver software fast helps us respond to changes as well as get features out that benefit our customers.
Containers play a vital role in dependency management and act as a packaging mechanism for bundling software into portable processes.
Ever since we’ve moved to containers our philosophy evolved around keeping it simple. Therefore every microservice git repository has a folder for source code, a JenkinsFile for CI/CD, a dockerfile that describes the dependencies of our software and a deployment YAML file that describes the services infrastructure as code. Therefore keeping source repositories very simple
Keep source code simple
Kubernetes
Kubernetes at Webjet is our go-to orchestration platform for running distributed systems, allowing our engineering teams to become way more efficient in delivering and running software. Kubernetes also allow us to pass ownership of production services to self-organised development teams, making teams self sufficient. As we build out more features for our system, we would add them is loosely coupled services instead of adding more code to our legacy code base. You may read about our monolith to microservices journey in the link below:
We’ve written about our story “Monolith to Microservices” which dives into our journey of breaking down our legacy application into microservices using containers and Kubernetes. For many companies, it’s not always possible to completely decouple the entire legacy system into microservices.
Our approach was to target low hanging fruit, moving parts that are easy to move that have low impact to the over all system if something went wrong. Another approach was to make a decision whereby we would not tact on new features to the legacy system, but instead build out new services for new features. These new services would go into Kubernetes. By following these two principles, we were able to shrink our legacy system over time.
The legacy system still plays an essential role in our business and it would not be of value to invest more development time in further decoupling and rewrite unless new features come up that allow us to prioritise and do so.
As the legacy system shrinks in size, it’s stability over time also improves since no big changes are being made to its code base. Our microservices journey has taught us a lot about the benefits of container and container orchestration systems. Was there a way we could overlap the benefits of containers and Kubernetes with our legacy system ?
Windows Containers
At Webjet our move to container based software has had a number of benefits which resulted in faster delivery, reliable software and productive engineering teams. Moving our legacy application to containers would allow us to inherit all those benefits allowing us to deploy our legacy system more frequently. The health probe and self healing features of Kubernetes will allow us to add a great degree of stability to the legacy system. More-so containers scale well especially when scheduled using Kubernetes it allows us to run a legacy process per CPU core. Using horizontal and vertical autoscalers would allow us to scale the system down during off peak and ramp up during peak times. With the current infrastructure, it’s not a simple task to scale up our system.
To get the benefits of containers and Kubernetes, is where Windows containers come in. The aim was that we could shift the code base to Windows containers with minimal or no changes to code.
Challenges & Highlights
Moving our codebase into a Windows container was fairly straight forward. Microsoft provides a base container image on Docker Hub, with the latest Windows Server 2019
FROM mcr.microsoft.com/dotnet/framework/wcf:4.8-windowsservercore-ltsc2019
This base layer already has IIS web services installed, so it’s just a matter of adding our compiled code to it.
Our first and most obvious obstacle was that we knew we needed a Kubernetes cluster capable of scheduling windows containers. Luckily, since we’re running in Azure, Microsoft announced General Availability of Windows node pools for Azure Kubernetes Service.
This means we can run Windows Server Core 2019 nodes in our existing cluster with relative ease:
az aks nodepool add \
--cluster-name $CLUSTER_NAME \
--name="windows-server" \
-g $RESOURCE_GROUP \
--node-count=2 \
--os-type Windows
Once deployed, we can see Linux and Windows machines running side by side:
Windows and Linux side-by-side
We are able to schedule windows containers using the same deployment specs we use for microservices. When writing a deployment spec, its important to use node selectors to ensure your Windows services run on Windows machines only, by adding a node selector:
nodeSelector: "beta.kubernetes.io/os": windows
What about our database ?
It’s very important that our legacy application has access to its database. The legacy system needed to run on the same Azure Virtual Network as the database to ensure reliable connectivity and low latency.
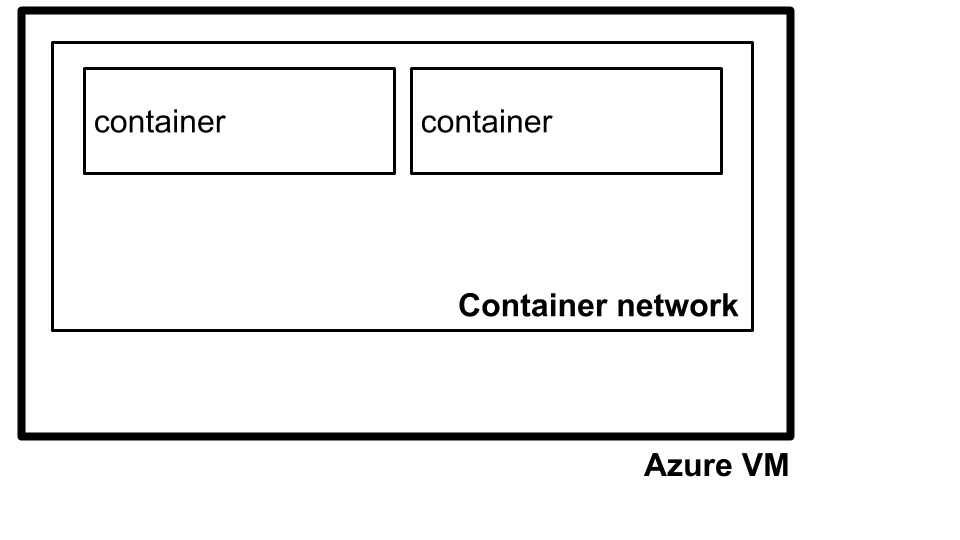
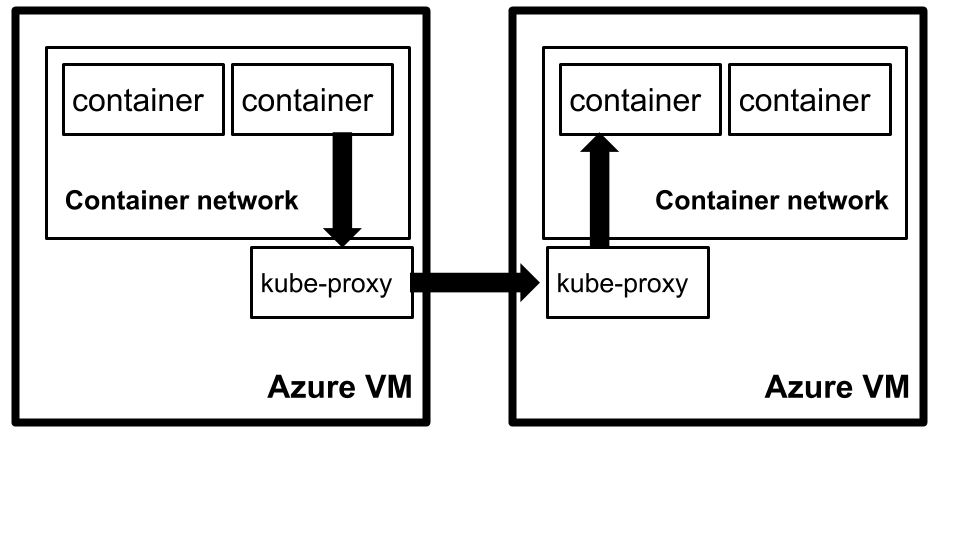
To achieve this, we followed a two step process. Firstly, containers in Kubernetes run on isolated container networks per machine as illustrated below.
basic container network
By default, containers on one machine cannot talk to containers on another machine. Kubernetes solves this with kube-proxy
container-to-container networking
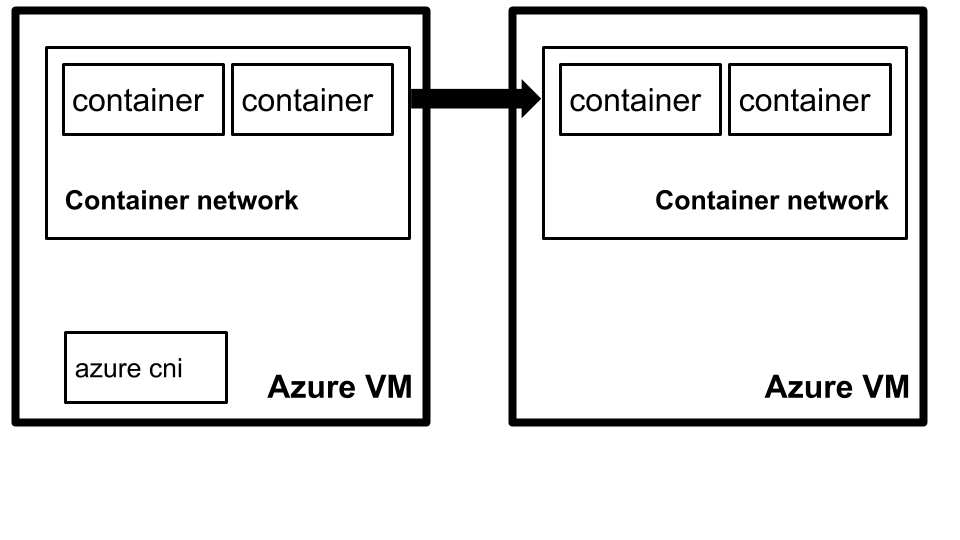
The challenge is that kube-proxy is designed using Linux iptable features provided by the kernel, which are not available in the Windows operating system. In order to get containers to be able to talk between machines, we use the Azure Container Network Interface plugin (Azure CNI). This plugin allows all containers in Kubernetes to get an IP Address from the Azure Virtual Network IPAM tooling
Azure Container Networking
This means our containers can now talk freely between Azure Virtual Machines as well as other Azure services on the Virtual Network since they get an Azure private IP address on the Azure network. This is essential for networking to function as well as our legacy system to be able to talk to its database. The next challenge was to see how we would bridge the Kubernetes Virtual Network with our existing database network in Azure.
Virtual Network Peering
Azure networking allows engineers to seamlessly peer Virtual Network subnets to one another using a feature called VNET peering. This allows us to connect our Kubernetes network to our database network. The two peered networks would communicate with one another over Microsoft’s private network:
Virtual Network Peering
There are two points to note here. 1) Is to ensure you allocate enough IP addresses in your Kubernetes subnet and configure Azure CNI to allow for more IP addresses to be available to containers in Kubernetes. The default number of IP addresses available is set to 30, which we increased to 110.
2) Thereafter we also had to ensure there was no subnet overlap between the two peered networks to allow peering to succeed. Peering networks in Azure is only possible if all network subnets have unique ranges that do not overlap.
Time Zone & Culture Settings
For our legacy system to work without significant code changes, we need the timezone of the server set to Australian time. Firstly all Azure VM’s part of the Kubernetes cluster runs in UTC time zone. This is the default and a good practice for servers to maintain. However, our legacy system relies on Australian time zone and since it’s quite a large complex codebase, there would be a significant effort required to change and test the impacts of running in UTC time.
The challenge is that windows containers cannot run in a separate timezone to the host. The “Set-TimeZone” command that triggers a system call to the host operating system is blocked in windows containers and triggers an Access Denied error. In Docker it’s considered best practice for containers not to manipulate the host operating system. However since Windows container runtime does not offer the ability to run containers on a separate time zone, we had to come up with a solution.
To workaround this problem, we’ve built a daemonset that is a specialized pod that runs on each node in the cluster. When the pod starts up on a existing or new node, it’s sole purpose is to perform an SSH command to its host and set the timezone. The daemonset gets its host IP address from the Kubernetes downwards api. Using SSH allows us to perform the command on the host, without a system call through the container runtime..
Set-Timezone DaemonSet
Logging and Monitoring
In Docker, the best practice for writing logs is to send them to stdout by default. This ensures the container runtime can gather logs of each container on the host. If the container throws an error and terminates, the container runtime would have the logs for that crash on the host. This helps us achieve centralised logging with log extraction services like Fluentd.
There are two problems at a glance. Firstly windows services do not always write their logs to stdout. Our system writes all its logs to Event Viewer in Windows. The second problem was even if our application was writing to stdout, The IIS process that would run as process 1 inside the container does not write its child application process logs to stdout either.
In order to get all Event Viewer logs out to stdout, Microsoft have built a Windows container tool set on GitHub, with the purpose of improving Windows container experience to align some of the missing bits that Windows containers have in the eco-system. “LogMonitor.exe” helped us get all our Event logs to stdout so the logs could be extracted out of the container to achieve centralised logging.
Performance and Stability
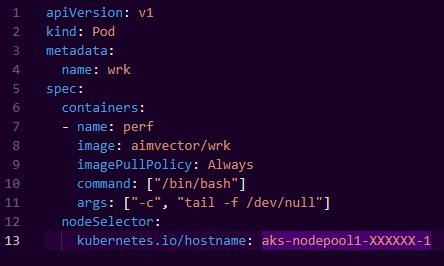
The final test for us was to ensure the system is stable over time. To test this out we’ve built up a simple performance test that would perform constant flight searches on the stack using a utility called WRK.
We schedule a number of “wrk” containers as pods on Kubernetes running inside the cluster with a simple pod spec
wrk – an HTTP Bench marking tool
We can ramp up traffic by adding more wrk pods, and leave this running for a couple of days to look out for things like the process health, system health, memory leaks and any unforeseen stability issues that may arise.
So far our testing in terms of performance and stability is on par with the current legacy infrastructure. The process has been pretty seamless and smooth helping us to transition to a container based infrastructure quite soon.
What’s Next?
Next up, we will be shifting our focus to the existing CI/CD pipeline for our legacy application. There are a couple of challenges remaining:
Since our container image can only build on Windows Server Core 2019, How do we build the container image in our existing build server ?
Configuration and Secrets – Since our legacy system relies heavily on a transformation process to inject secrets and configuration files per environment, What would this look like in the Kubernetes world ? Kubernetes provides the ConfigMap and Secret API which does not currently align with our methods of deployment configuration and secrets for the legacy system. Our engineering teams will come up with a strategy to evolve this process to be container native.
These are exciting times ahead, and if you are interested to see more on these CI/CD developments and other activities in the platform engineering space, stay tuned to our tech blog.
I joined Webjet back in May as a Master of IT & CS graduate from RMIT.
When looking for work I was looking for a place with a friendly and inclusive environment, which is not too small but not too big, is Australian with a growing international presence, a profitable business but still people-focused. I knew a few guys at Webjet and thought they were the type of people I could see myself working with.
The day I started I really felt how supportive and attentive is all the staff at Webjet, how I was part of the team from the get-go, how collaborative all the teams are, no ‘us’ and ‘them’ mentality.
I really enjoy being exposed to various technologies and products, various tech stacks, I was impressed with Webjet’s commitment to technology and quality of work.
All teams at Webjet have full operational product ownership, meaning a team has full responsibility from kick-off to release, support and operation of the product, which ensures a great customer experience with our products.
Currently, I work in the ‘Flights’ team, which is responsible for everything that has to do with searching flights from various vendors, showing best prices and providing the best value for our customers.
I enjoy working at Webjet, I believe I have gained a lot of new knowledge and constantly growing as a professional. There are always challenging issues to solve and an opportunity to research new tech and ideas. As part of Webjet culture, there is a great focus on continuous improvement and support of all staff members.
I’m always encouraged to bring new ideas, all thoughts are respected and taken into consideration which in turn encourages developers to provide the best product for our customers.
As an example, I was able to develop and deploy Openresty solution to solve a universal URL redirection problem. I didn’t have prior experience in this but was encouraged to learn.
I joined Webjet back in April as a Master of IT & CS graduate from RMIT.
Working as a Developer at Webjet, I got to pick up coding tasks or stories that have been planned for the current sprint. Following an Agile development model, each morning we have a stand up where we discuss what we’ve worked on and if we have anything blocking our work. The rest of the day is spent on working through the stories, complete code reviews and deploying completed work into production. I’ve got to learn many new things and spend time with team mates asking questions and learning from their experience.
I’ve loved the variety of the work I got to do. Through the projects I’ve gotten a chance to work on have many different components like building the Jenkins pipeline, developing and maintaining the front-end applications and micro services. With any work I pick up, I’ve had the liberty to tackle it however I want, which often leads to a chance to learn something new. That’s something I love about working at Webjet. I’ve got ample opportunity to learn, either through the learning tools provided by the company to up skill, by my own research or discussing with the team I am a part off.
Being a fresh graduate, I still have things to learn and working with more experienced developers can sometimes be overwhelming and confusing especially during discussions. However, the few months that I worked at Webjet, I found that the team members are more than happy to explain the more complicated concepts or walk me through a task.
Building a microservice platform that is scalable and can handle hundreds and thousands of requests per second is a difficult task even on modern cloud platforms.
There are many challenges in building modern distributed system and monitoring these systems can be particularly tricky. In this post, I’d like to do a deep dive into how we designed a metrics platform that is able to scale, aggregate and feed in to a monitoring solution to support reporting on anything in the system that a developer or operator wants to track.
As our engineers at Webjet build out our distributed services over a global landscape, our recent goal has been to scale these systems linearly so we are able to achieve 30,000 requests per second with latency as low as 2 seconds for each request.
There are several challenges with designing this type of platform. We have had to tackle many of them so far, including:
Handling high volume of incoming requests and more importantly how to handle socket connections on the platforms edge
Fanning out connections from the edge to different microservices within the platform. Managing more socket connections!
Fanning out connections from internal services to external providers from whom we get hotel content from. Handling outbound connections
Caching
Contention in network
Dealing with high CPU tasks
More importantly and for this post: How do we track each individual request and report on it without adding massive contention to the system. And do this within a reasonable cost!
Our Starting Point
Our starting point was using StatsD. StatsD is a powerful stats aggregation service that got our attention because it’s very simple to deploy and operate. There are many client libraries so it works across multiple platforms.
StatsD is able to track counters, timers and gauges. Counters are important for us to monitor throughput of each microservice, i.e. Requests per Second. Timers are important to track how much time incoming requests, internal and external requests take to complete.
To operate at a very large transaction volumes, we will need a scalable a metrics system. The first problem we faced with our StatsD server was that it became overloaded because it is a single threaded NodeJS server and aggregation on this server was CPU bound, so metrics were dropped.
Our first intentions were to scale the StatsD server, however when you run multiple instances of StatsD, your aggregation will split among these instances and your metrics will become skewed. Folks at Anomaly wrote a great post about three ways to scale StatsD.
To summarise that post, the StatsD community have built a cluster proxy to overcome the scaling issues by using clever hashrings to ensure metrics go to the same StatsD backend and are aggregated correctly. This proxy however becomes the new bottleneck so to overcome this you can run a few of these proxies by running one on each host as described in the Anomaly blog post.
A service would make a call to the StatsD proxy on the same host which would pass on the metric to an external host running a StatsD server.
With our platform, we did not want to couple our infrastructure to the metrics servers. We would prefer the platform to push metrics to an external endpoint and not rely on components running inside our microservice platform. The StatsD proxy would also need to be aware of all the running StatsD servers behind it, therefore scaling is not as simple as increasing a Kubernetes deployment replica value. The proxy would need to be reconfigured to be aware of the new instances as you scale up or down.
Prometheus to the rescue
The core problem with StatsD is that the aggregation happens on the server which you need to scale. Our solution: Move the aggregation to somewhere else. Prometheus is a powerful metrics time series database that allows high performing aggregation. It also uses a “pull” model instead of “push” which means it will reach out to endpoints and scrape metrics, so even at high throughput, it can scrape many endpoints efficiently and does this asynchronously outside of the main request path.
You are probably thinking, “So what happens to StatsD???”
The folks at Prometheus have an awesome metrics converter that is lightweight, can be load balanced and deals with the task of receiving StatsD metrics and converts them into Prometheus metrics whilst also allowing Prometheus to scrape them periodically.
This design removes the stress of aggregation at the receiving end so even at high request volume, metrics can flow in at thousands of requests per second whilst being scraped every 5 seconds or so, outside of the main request path.
A microservice would send its statistics using StatsD client to a single endpoint which is load balanced. The stat would hit any StatsD-exporter and would be made available for scraping.
Prometheus will scrape the StatsD-exporter and make the metrics available in its time series database for reporting in Grafana.
Running StatsD-exporters as a Kubernetes pod allows you to scale up easily. Prometheus has Kubernetes service discovery built in, so if configured correctly you can allow Prometheus to use the Kubernetes API to find your StatsD-exporter pods and start scraping them almost immediately when they becomes available.
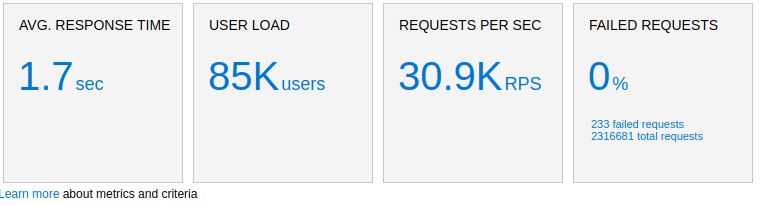
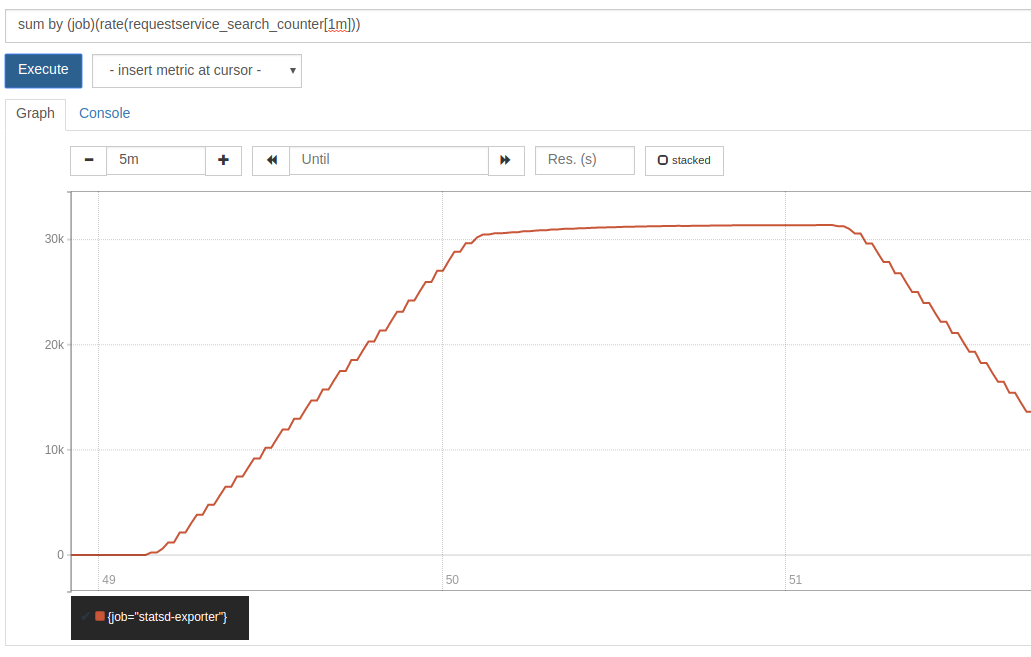
Load testing this solution, we are able to track 30,000 requests per second with a simple F4s series VM in Azure running StatsD-exporter and Prometheus.
From our Azure cloud load testing dashboard we can see our 30 000 requests per second.
These are request counters and timings from the client side :
On the backend we can see Prometheus scraping similar values from StatsD-exporter.The goal is to make sure we see the same numbers on the client and server side, so we do not have any discrepancies between the monitoring and the load testing platform.
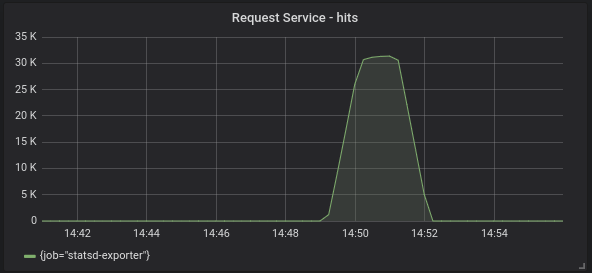
From then onwards, we can feed that data through to Grafana for our monitoring dashboards:
Having a scalable metrics platform like above not only allows us to track things in the microservice world, but also saves a lot of costs. StatsD adds very little client overhead as well as minimal friction in the platform’s network. Since we have full control over how much data we want to keep and archive, we can fine tune the cost model. With most third party offerings, the cost of running hundreds of microservices quickly adds up to a couple of thousand dollars per month because there is a flat fee per gigabyte of data.
We hope this article helps you as an engineer make smarter decisions when deciding on using or building a new scalable metrics system.
As the paradigm shifts more to container workloads and microservices, Webjet was looking for a way to deploy containers as well as manage them. In part one we dived into the journey of microservices, our traditional Azure Web App architecture and how we started adopting container workloads. We learnt to write systems in golang and dotnet core, how to write Dockerfiles and build up a series of base images. Most importantly we built the foundation of what’s required to build and manage containers effectively.
This era of our container journey plays a big role in how things turned out. When we started looking at container orchestrators, there were only a few and not all of them were production ready. If you read our blogs you should know by now that Microsoft Azure is our “go to” platform, so it is where we started. At the time (late 2016), the most production ready platform was DC/OS . Kubernetes was not released yet and Docker Swarm was in private preview. For us, the orchestrator needed one key feature..
Run my container and keep it running!
The main challenge was building a CI/CD pipeline that would plug into a container orchestrator and have a service discovery mechanism, so we could route traffic from the customer’s browser, to the individual containers, no matter where they were running. We wanted to be platform agnostic, so we could run on any orchestrator. The good things about every orchestrator, is that they generally provide built in service discovery and have a method of defining an “Ingress” (Where network traffic enters) through a public IP address.
Batman’s Operating System
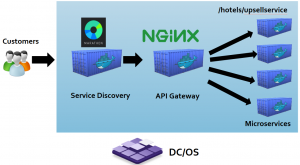
For DC/OS, it was Marathon and NGINX:
It serves the purpose of “Ingress” and has a public IP address. Customer traffic arrives at Marathon, and it can find other containers inside the cluster without having to know private IP addresses. Marathon routes traffic to our own customised Nginx container, which in turn serves as the API gateway. The API gateway routes to the correct container based on its URL path and terminates SSL traffic and sends traffic privately to microservice containers.
Ask Jeeves
To solve the CI/CD piece, we turned to the popular Jenkins build tool. One key feature that Jenkins provide is ability to write pipeline as code .
Writing a declarative pipeline definition as code allowed the team to have version control for their CI/CD pipeline side by side with the code. It also means no one must manually create pipelines with the web user interface. Pipelines can be parameterised and re-used across new microservice implementations. This allows us to move faster when implementing new services and we don’t have to spend time designing the pipeline from scratch. The Pipeline file defines the CI/CD process and the Dockerfile defines the application and its dependencies. These two files form the ultimate source of truth and allows for a fully automated deployment platform where the source of truth is in the source control repository and not in the snowflake environment.
Once we had these two components in place, CI taking care of the image building and pushing to Azure Container Registry, CD taking care of deployment to DC/OS and Marathon taking care of service discovery, we had a foundation in place to deploy our first production service.
Webjet chose a small, isolated, non-critical piece of functionality which we pulled out of the legacy monolithic stack and containerised. It became the canary that would test out the container CI/CD and orchestration system.
One thing we were not satisfied with, was the lack of secret management in the open source version of DC/OS. This version did not support secret management which at the time was an enterprise-only feature. We wanted to avoid enterprise agreements and vendor lock ins our docker environment. We preferred the ability to lift and shift to various orchestrators when the need arises. Our apps needed to be cloud native, and therefore run anywhere.
Capt’n Kube to the Rescue
Roughly a week into production, Microsoft announced Kubernetes general availability on the Azure Container Service platform (ACS)*. During this time, containers were a new thing on Azure. For us being new to this as well, we were fortunate enough to mature alongside the platform as Kubernetes, which itself was just over 2 years old. We were able to leverage our relationship with Microsoft and worked together with open source teams at Microsoft and share experiences of the journey. Though these close ties we ensured that our roadmap aligned with that of Microsoft and the Kubernetes upstream.
Microsoft alignment with the upstream Kubernetes community and their massive contribution to open source is what got us excited about Kuberenetes. We could finally build a microservice stack on a cloud agnostic and cloud native platform. It can literally run anywhere.
Our next move was to deploy a mirror of what we had on DC/OS, but this time use Kubernetes as the platform. The benefits of our initial CI/CD process were realised, and we seamlessly plugged into the new platform. We replaced Marathon and the Nginx API gateway with Kubernetes Ingress controller. Ingress takes care of service discovery and URL path routing within the cluster. It also runs through a public IP address and operates at the edge of the cluster for receiving inbound customer traffic.
With CI/CD in place we could deploy our non-critical microservice to this cluster and the services were accessible by the customer over the same URL.
Once tested, all we changed was the endpoint where the domain name was pointing (from the DC/OS IP to the Kubernetes Azure Load balancer IP) and traffic started to flow to the new implementation. We switched over from DC/OS to Kubernetes within a week after we went live. How dope is that?
You’re probably thinking, “how are you monitoring these containers and VMs?”
In Part 3, we will look at logging and monitoring and how Webjet embraced open source tools to simplify the entire monitoring and observability process.
Until next time!
* One thing to note is that ACS was not the managed Kubernetes version (AKS) we know of today
Micro-services have been a hot topic for us folk at Webjet. Like many other software teams, at Webjet, we have been working over the years with what we would more recently call a monolithic architecture. Being faced with changing the way we engineer our solutions to meet the scale, agility and momentum our business demands, we turned to micro-services as a solution for delivering new features. This decision led to an unexpected journey with Docker which we would like to share with the broader community
Where did our journey start, what is a monolith ?
In simple terms, a monolithic application (monolith) is an application where the user interface tier and its data access code are stitched together in a single application on a single platform. As the application grows, more service tiers and application features are introduced and therefore the complexity and configuration of the application and its environment increases. It becomes harder to make even the smallest changes and introducing a breaking change can happen at the blink of an eye. Scaling therefore also becomes a resource-expensive effort, as only whole instances of the entire application can be scaled even though each layer has different load and resources requirements. This leads to over-scaling some layers, but under-scaling others.
So how did we break the shackles of the monolith?
Over time, we started slicing up the monolith into separate services and user interfaces that would become isolated. We would deploy each of these services separately using the Microsoft Azure WebApp platform.
Although this was the first step to a micro-service architecture, we introduced a lot of complexities in our build and continuous integration pipelines. As the number of services grew deployments and setting up CI/CD pipelines took a lot of unnecessary time. We were at a point where we could see that the way we were building and deploying our micro-services would soon hit a bottleneck and slow our journey down.
Where the unexpected journey happened.
Being focused on continually improving our engineering processes, we started a review of how we were deploying our WebApps in our CI/CD pipeline.
WebApps allow you to deploy services on separate servers or to the same pool of servers. Deploying a tiny micro-service to its own server does not sound very efficient. Deploying a few of them sounded like a better option, but what if you have one resource hungry noisy neighbour?
This is where Docker comes in.
Docker is a technology that allows us to build all application code, its operating system, configuration and dependencies into one single entity called a container. For us, it made sense to start building new services on container technology and start the decoupling process of the monolithic application. As a group, we’d have to identify all the components of the monolith that we can break apart, -.e.g flight search, hotel search, shopping carts, up-sell services, autocomplete services, small UI components, etc. , etc.
For the shift to Docker to happen, we needed a massive technology and mindset shift:, introducing new programming languages, new operating system platforms, new scripting frameworks and many more.
Docker introduced true immutable applications, the ability to run cross platform and on any cloud. Our Docker solution is also highly scalable and deploys really fast! I can go on and on about the beauties of Docker, but I’ll leave this here if you want to read more on what it is.
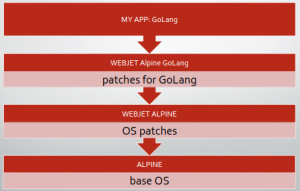
With Docker, we can build layers of images. So as an example, let’s say we use Linux Alpine as a base operating system. Our DevOps team can then build a Webjet certified Linux Alpine image with all the required security patches. This can be used to build a other images that have the dependencies for applications to run, for example, a popular programming language built by Google called GoLang.
We embarked on a mission to start building out our base Docker image library to make it really simple for teams to build micro-services on different languages. If I was a developer and I needed to use GoLang as a language, I can simply build a new Docker image for my application and inherit the Webjet GoLang image. An example hierarchy can look like this:
Now, Webjet development teams can build services top down not worrying about the low level configuration, whilst DevOps and security teams can architect the base images from bottom up to ensure they all stem from the certified base images. This keeps vulnerabilities to a minimum and keep the images lean and small as possible.
We’ve also utilised Azure Container Registry for hosting our Docker images which makes it easy to start integrating continuous delivery pipelines and deploying micro-services.
This brings us to Part 2 of this series where we’ll be covering “Container Orchestration” and Kubernetes: How we at Webjet deploy and manage a large number of containers within the Microsoft Azure cloud infrastructure.
The hotels team at Webjet got tasked with developing a new auto complete feature for our site, that would be capable of sub second suggestions across thousands of cities, localities and areas, and be smart enough to figure out near matches.
The system we had currently that was part of our monolith was a very basic text based query engine that was not very performant, and very rigid in what results it returned.
Given our technical direction, to split out our monolith into Microservices, we had an opportunity to come up with an innovative way to solve the problem. Our initial reaction was to implement an Elastic search engine, but after further exploration we decided to try out Azure’s Pass offering, Azure Search. In theory would give us similar features, without the extra effort of managing the search system.
The three MVP features that were critical to our service were:
Result prioritization
Fuzzy logic to cater for spelling mistakes and near matches
Synonyms
Staying Relevant
Azure Search has a Suggestion API feature (https://docs.microsoft.com/en-us/rest/api/searchservice/suggestions), but we decided not to use it as it was not very flexible, with limited options when it comes to search result prioritization and “fuzzy” search terms with spelling mistakes.
With the Suggestions API not meeting our requirements, it was back to the drawing board, attempting to query the Azure Search API directly. To start off with, we tried querying the underlying Lucene index with just a Lucence wildcard search:
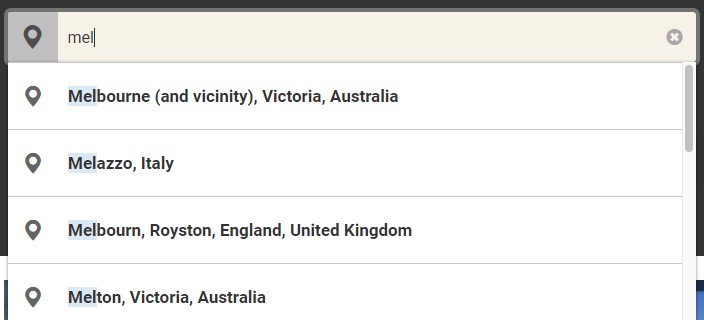
While this worked well and returned a list of destinations, it wasn’t context aware, and did not prioritise the results. A search ‘mel’ returned:
Mele, Vanuatu
Melle, Germany
Melazzo, Italy
Melaya, Indonesia
Wait! Where is the most liveable city, Melbourne???
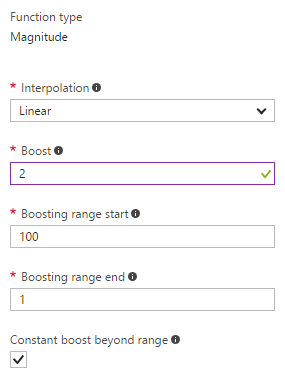
Melbourne, Victoria, Australia couldn’t even make it to the top 4. We wanted the ability to prioritise certain destinations based on sales volume and other business decisions. To enable custom priorities, we needed to use Scoring profiles. Scoring profiles are a way to boost or decrease the value of @search.score, which determines how relevant the result item is to the search term.
We added an additional field to our search called priority, a numeric value, scoring important destinations with a low value and less important destinations with a higher value. We then set up Priority field to boost the search relevance score for those destinations.
The maximum we want to boost is 2 and the linear interpolation here means the closer the priority to the end of the range, the more weight we want to throw in the score. As a result, the following call gives us Melbourne as the top match.
The second feature that needed is fuzzy logic. This would allow us to still return relevant results even if the user has made a spelling mistake or typo. For this, we first looked at using the Edit Distance based fuzzy search query capability built into the underlying Lucene search index. To do a fuzzy search, we specify the edit distance in each search term. For example, “sydbey~1” can match “sydney”.
This is what we’re after, however, it comes with some limitations:
The maximum Edit Distance you can set per query is 2, which means the search term can have a maximum of 2 mistakes to still be considered a match.
Edit Distance based fuzzy searching takes a huge hit on search performance.
As we needed to cater for multiple spelling mistakes and sub second response was critical fuzzy searching off the table we considered other ways we could cater for our needs of handling spelling mistakes.
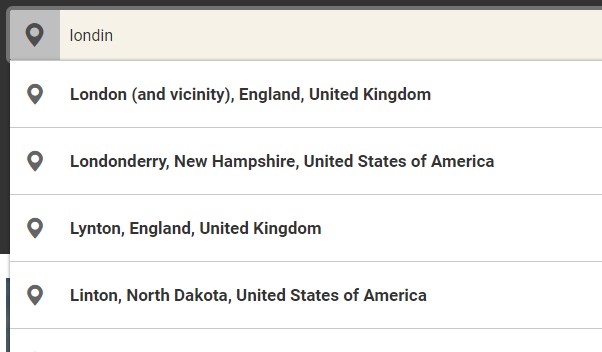
We came across Custom Analysers (https://azure.microsoft.com/en-au/blog/custom-analyzers-in-azure-search/) which could handle simple fuzzy logic, and decided to give it a go. We created a phonetic analyser which consists of a standard tokenizer and the phonetic token filter. This custom indexer builds an indexer of all possible tokens of a word based on how the word could be pronounced. This feature would cover a much wider scope of mistakes, rather than just handling one or two typos. We now can handle cases where a customer simply is unsure of the spelling. With this combination, typos such as londno, londin, melborn and koala lamper are resolved to their expected destinations (London, Melbourne and Kuala Lumpur) with very little hit on performance.
Optimizing for Performance
With our search finally achieving the search results that we expected it was now time to tune the performance. We didn’t realise when we started, but performing wildcard queries against a Lucene search index takes a huge hit on performance.
Detailed in the above blog from Microsoft was the use of Lucene EdgeNGramAnalyzers. This custom analyser is ideal for searches where you are performing a partial word search such as our customers would be doing. The indexer tokenizes each word of our destinations into all combinations of its prefixes. For instance, “Melbourne” will be indexed as the separate tokens which cover all partial spellings of the word, ie: [m, me, mel, melb, melbo, melbour, melbourn, melborne].
With each of these tokens now stored in our index we can drop the wildcard from our query simplifying the query and making it more effective. Each the search can just perform a lookup of these tokens that have been created at index time rather than calculating them on the fly during search time.
Search Term Synonyms – When not all your mistakes are spelling mistakes
We were quite happy with the way it worked then we typed in “goldcoast”… it couldn’t suggest Gold Coast, Queensland, Australia which is one of our top destinations.
Finally, we figured out we also wanted to be able to handle search term Synonyms. For example, our analytics data showed that a very common customer search term that was returning no results was “goldcoast” when a customer means to search for “gold coast”. This was not picked up as a phonetic match as the index has no way of knowing that the single word “goldcoast” should be two words. Instead, we needed to also add these known mistakes into our index in some way.
Azure Search does provide a way to do this in the form of Synonym Maps (https://docs.microsoft.com/en-us/azure/search/search-synonyms) that let you match any known mistake to a word which represents the correct way it is spelt instead. We opted not to in this circumstance as it would mean using a preview version of the Azure Search API.
We instead just created an additional field against each of our destination records which holds a collection of all possible mistakes for that destination. Such as “goldcoast” against our Gold Coast, Australia record. It turns out to be a much more manual process since we need to manage these synonyms for each destination record, however it allows us to maintain full control over which records will appear for each of these non-phonetic mistakes.
Onwards and Upwards – Hotel Name Searching
With our new search live and taking traffic, our team analysed stats, and found a significant percentage of our customers were searching for a specific hotel. Our current hotel listings are stored in thousands of JSON files which are hosted in Azure blob. With the knowledge we’d gained setting up our destination search and Azure Search’s JSON Indexing feature (https://docs.microsoft.com/en-us/azure/search/search-howto-index-json-blobs) we were able to quickly and painlessly add hotel data to our search index as well, something that would never have been possible in our old system. (Note: Azure Search blob indexing is currently still in Preview however, we accepted the risks as it did not affect the core functionality of autocomplete)
Hope this blog gave you guys a good understanding of our use of Azure search. At the start of the project no one on our team had ever used any of these technologies and it was a rewarding experience to deliver a new feature that help our customers and addressed Webjet’s needs.
We’ll be publishing more blogs on our journey, as we take to scalpel to our Monolith.
We gratefully thank Geoff Polzin, a senior consultant from Readify, for his contributions to this blog. Geoff was part of this journey too.
This article explores the how we established our UI Pattern Library which is bringing visual consistency to our customers and significant time savings to our development team.
Background
In early 2015 I joined Webjet as their first in-house UX Designer.
At that time Webjet operated two brands in four countries and sold seven distinct products. To service smartphone users these products utilised a mix of independent mobile sites, responsive design sites, and a native iOS app. Each solution had been built at different times, sometimes by different teams, without an in-house designer across them.
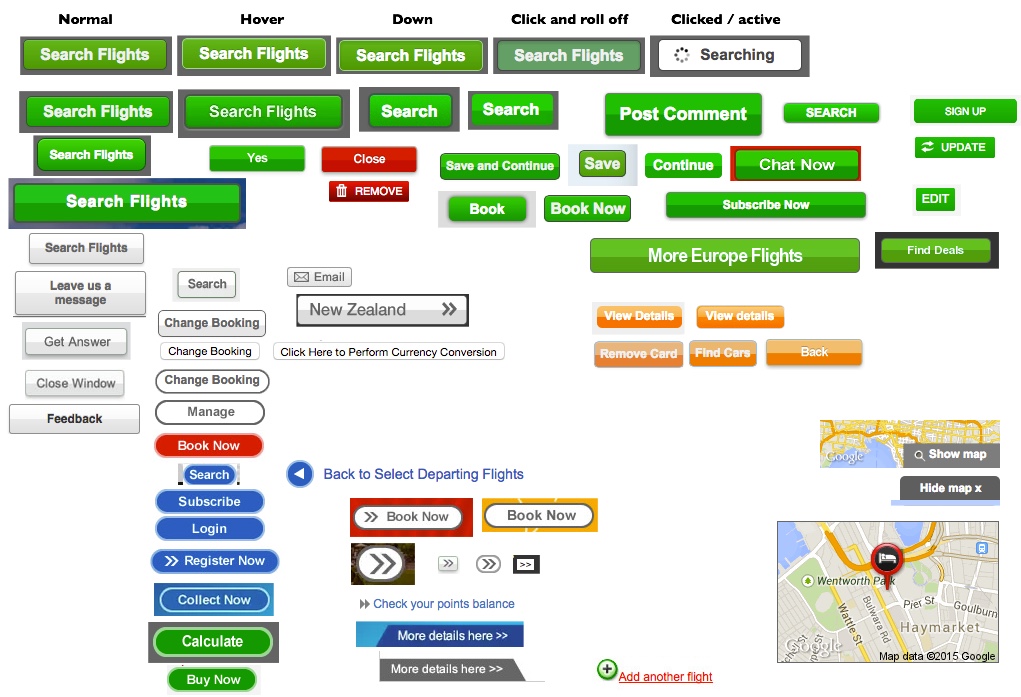
The Webjet user interface had been influenced by many design trends over a 15 year period. Buttons appeared throughout the properties with a mix of 3D bevels, gradients, thick solid borders, drop-shadows, etc.
When my first UX project was approved the dev team requested full design specifications – button colours, hover states, text colours, paragraph margins, etc.
Example Design Specifications
There were no UI standards for anyone to refer to.
Additionally, it became apparent that the development team had a resourcing challenge. UI elements were regularly implemented by experienced back-end developers with only surface-level knowledge of front-end technologies. Even with the same design specifications, two developers could deliver widely different implementations, which reduced opportunity for UI pattern reuse and complicated the site’s maintainability.
Plan of attack
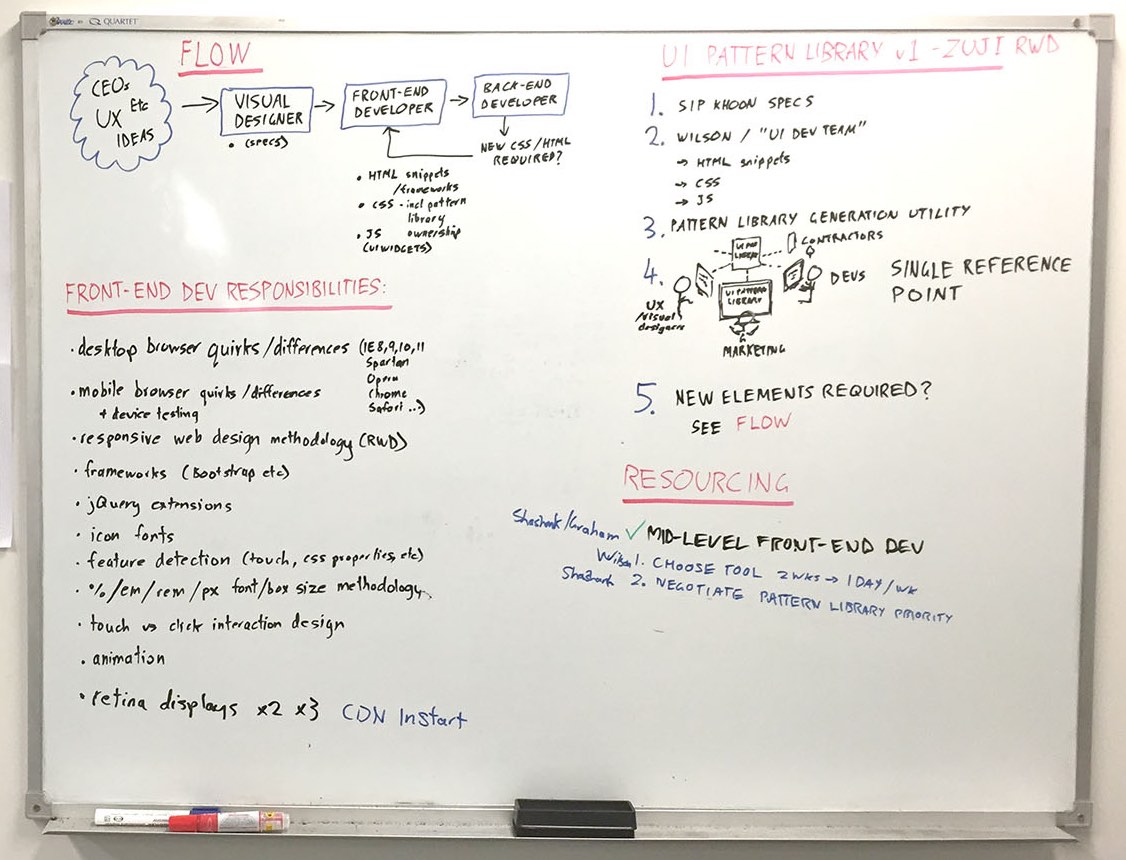
I needed to establish the extent of the UI disparity in a format that all stakeholders could understand. To do so I built an UI inventory.
The steps to build an UI inventory are simple – start with a blank slide deck, take a screenshot of any new/different UI element you encounter while browsing through the site, then group the screenshots into categories.
To address the lack of standards and resourcing challenges I worked closely with the key stakeholders including the lead developers, marketing, product owners, visual designer, and the most front-end savvy developer within the existing team.
The goals were to:
Get buy-in for the establishment of a UI Pattern Library
Establish a formalised workflow for UI design and implementation
Establish a dedicated front-end team
Clarify ownership of the UI Pattern Library
The UI Inventory illustrated the need for a centralised UI Pattern Library was undeniable and the stakeholders clearly saw the opportunity for increasing development efficiency and providing a consistent user experience. The discussion then moved to how to move forward given the broad impact of such a tool.
In the whiteboard photo below you can see the outcomes of a stakeholder workshop where we answered the 4 goals above. This is explained further below.
UI Pattern Library – Workflow & Responsibilities
Workflow
We established the following workflow for new UI work:
All UI elements are to be designed by a Visual Designer, who will provide specifications to the yet-to-be-created Front-End Team.
The Front End Team will then create the HTML snippets, CSS, and Javascript (for UI widgets), place them in a centralised, organised, well-commented repository in GitHub. This will be known as the UI Pattern Library repository.
Back-end developers will then utilise the pre-written front-end code.
If projects manage to slip past the Front-End Team, the back-end developers are to liaise with the Front-End Team who will create or refine the UI Pattern Library repository and involve a Visual Designer as necessary.
Ownership of the visual design was placed with the Visual Designer (in tight collaboration with the Head of Marketing).
Ownership of the UI Pattern Library repository was taken by our most front-end savvy developer, whom would become the leader of the Front-End Team.
Resourcing
We needed a dedicated front-end team to establish and reinforce this workflow.
To build the case for additional team members I listed out the typical concerns of a front-end focused developer to contrast against the concerns of a back-end focused developer.
Responsive web design methodology (breakpoints, media queries, etc)
Frameworks (ie Bootstrap)
Javascript library extension utilisation and authoring
Icon font implementation
Feature detection (touch, CSS properties, etc)
Font & box size methodology (% / ems / rems / px)
Touch vs cursor interaction design
Animation
Retina image implementation strategy
Few back-end developers are masters of all of the above. It is a field that is constantly moving, and on-going research is required to efficiently cover off these topics.
The lead developers agreed this skill set was worth building an internal specialisation around, and they began recruiting a front-end developer to join this newly created Front-End Team.
Prioritisation
It became clear that the establishment and multi-brand, multi-product implementation of a UI Pattern Library was not going to be prioritised over existing project work.
To get the ball rolling, we ‘piggybacked’ an existing UI-heavy project (our Hotels website re-platforming) and started with standardising a single UI element – buttons.
UI Pattern Library Creation Process
Design
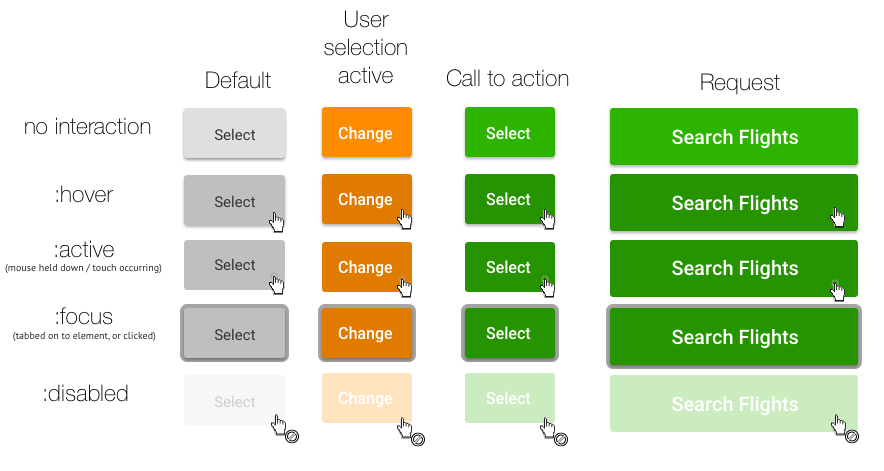
Following the workflow we established for new UI work, I created the specifications for a standard suite of buttons. These catered for the various use cases and states they would be seen in, with a focus on touch and accessibility.
We assessed various design influences for their respective usability qualities – skeuomorphism, flat design, Google material design, etc. Ultimately we settled on the following as it met a balance between usability (elements looking clickable) and simplicity (flat colour).
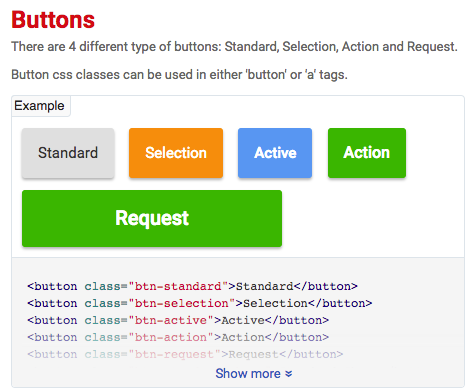
UI Pattern Library – Buttons
Front-end Development
Our front-end team chose to write the CSS styles in independent LESS files to avoid the all-in-one-file legacy they had inherited. These would then be processed to translate the LESS into CSS syntax, combine the independent files, and minimise the output for use in production environments.
Automation
We needed a platform that let marketing and visual designers see developed UI elements in various contexts before approving them to go through to production.
Our developers required details of when and how to implement UI elements.
After a bit of research and experimentation our lead front-end developer settled on a UI Pattern Library documentation automation tool called Hologram.
Hologram allows you to write your CSS styles as per normal (using LESS in our case) and then display the styles in a well structured and documented form. The documentation for each style is written in markdown. The output looks like this:
Buttons documentation by Hologram
We hosted the documentation on Microsoft Azure to get them online quickly.
Consumption
The GitHub repository allows our developers and 3rd parties to access and use the latest UI patterns in their projects. They can read the associated implementation details in the live UI Pattern Library, and copy HTML for use in their projects. We’ll share more technical details (involving Bower and tailoring HTML snippets for React use) in a separate blog article.
Expansion and outcomes
Now that the infrastructure was in place and we demonstrated button styles could be successfully centralised and consumed, we began building on this. As the project did not have prioritisation above existing work, we added elements that were being used in existing project work. I commandeered a wall beside the office’s main entrance to communicate the state of the UI Pattern Library and encourage use and involvement.
UI Pattern Library wall
Over the course of several months we built out a broad number of UI elements. Standardised headings, form elements, modals, tooltips, accordions, and more.
Initially all design specifications were created manually (colours, padding, margins, font size, etc) however in mid 2016 we switched to using Sketch Measure to automatically generate interactive design specifications. This dramatically reduced the time spent preparing the UI work for the development team, updating specs after design alterations, and the margin for error when interpreting design specifications.
We used the centralised model to educate the broader development team on how to address UI challenges such as retina display iconography and imagery, dropping older methodologies in the process.
It provided the front-end development team a blank slate to begin overhauling the multi-brand, multi-channel legacy stylesheet that they had avoided refactoring due to lack of prioritisation and fear of breaking functionality.
As the team continues to work on our customer-facing systems our array of legacy UI styles are phased out, and the centralised model allows us to manage our brand and customer experience in a far more agile manner.